
L’info, c’est l’éditeur qui la produit, c’est le bot qui la publie !
voir les précédents Botservatoires
Les bots ne se contentent pas de constituer des bases pour les revendre aux IA ni de les structurer en offres, notamment de media monitoring. On assiste désormais à la création de nombreux sites d’infos dont les contenus sont rédigés à partir des articles de presse collectés en ligne.
Les bots commencent généralement par indexer (crawler) les infos de création ou de mise à jour des articles ou photos (sitemap, RSS, têtes de rubriques), puis vont chercher (scraper) les articles qui les intéressent.
Pour cette activité, les bots prennent beaucoup moins d’articles que les entreprises de big data ou de media monitoring qui en récupèrent des milliers par jour. Pour de la republication, quelques articles par jour et par éditeur suffisent pour faire vivre un site de news. Le modèle économique est généralement la publicité.
S’il est rare de les voir remonter sur Google, certains de ces sites proposent de s’abonner à leur newsletter ou à leur fils Telegram, sur lesquels ils communiquent sur leurs articles.
Si l’article complet est disponible sur le site originel, il sera publié en entier (avec un lien vers la source, devenu inutile).
Par exemple : Article d’origine :

Article identique, mais complet, republié sur un autre site:

La nouveauté ? L’ l’IA facilite de nombreux services parmi lesquels le résumé, la revue de presse citant un ou plusieurs articles, la traduction à la volée qui permet avec un seul article d’en publier plusieurs dans toutes les langues…
Le Figaro :

Et son équivalent, qui correspond au résultat donné par un service en ligne de traduction automatique :

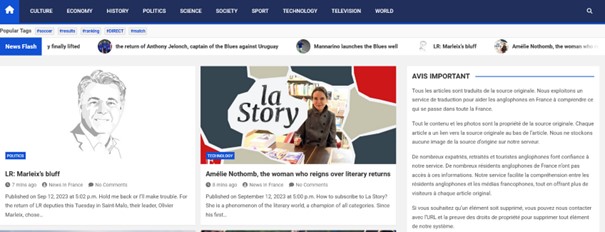
On peut même être gratifié d’un avertissement, qui explique la démarche. Près d’une reprise d’un article, on peut lire :
AVIS IMPORTANT
Tous les articles sont traduits de la source originale. Nous exploitons un service de traduction pour aider les anglophones en France à comprendre ce qui se passe dans toute la France.
Tout le contenu et les photos sont la propriété de la source originale. Chaque article a un lien vers la source originale au bas de l’article. Nous ne stockons aucune image de la source d’origine sur notre serveur (…)
Si vous souhaitez qu’un élément soit supprimé, vous pouvez nous contacter avec l’URL et la preuve des droits de propriété pour supprimer tout élément de notre système.
Evidemment, le site n’a pas de directeur de publication, et la page contact n’existe pas.
Ces sites de « news » ont généralement des maquettes assez sommaires, avec de nombreuses rubriques (alimenter toutes ces rubriques nécessiterait une vraie rédaction, qui semble assez absente).


Nous remontons sur Botscorner une soixantaine de sites qui publient des articles récupérés sur les sites de news.
Attention :
- à ne pas mettre l’intégralité d’un article dans le flux RSS ,
- à ne pas rendre disponible un article par le code source quand il est soumis à un paywall.